
🖋️ ARTICLE
🗺️ How I made the best map of William & Mary
How I improved OpenStreetMap around the William & Mary campusPosted by Jacob Hall
Posted by Jacob Hall
Hey! It's been a while. I'd like to share a frustrating story from this week.
Quite a few years ago, I bought a Google Pixel 2 to replace my iPhone 5c. It has been a great phone! However, it's getting old, and Google stopped promising software updates for it a while back. I was fine with that for a while, but now it's 2022 and I'd like some sort of update to my phone's operating system.
So, what custom ROM options are there for Android devices these days? After a bit of research, I landed on Lineage OS, a community project that's relatively well-known for breathing life into aging Android devices. It supports an impressive array of devices, and offers features I've come to expect in a smartphone.
So, the first thing you have to do to install a custom ROM like Lineage OS is to unlock the bootloader on your phone, allowing you to install your own operating system over the one it shipped with. Google proudly claims that you can do this, offering an "Unlock OEM" option in the developer settings of their Pixels. Unfortunately, my Pixel 2 refused to be unlocked. After so many tries and factory resets, Fastboot consistently reported that "Flashing Unlock is not allowed." It appears that this problem is relatively common with Pixel 2s, perhaps because I got a warranty replacement device back in 2018.
It bothers me so much that my phone is now obsolete, and the manufacturer won't let me install what I want onto it. I contacted Google Support to see what they had to say, and a lovely person by the name of Erick seemed genuinely sorry, but could only suggest that I send my handset in to Google for "repair." I might try sending it in at some point, but I can't afford to mail my phone away for a couple of weeks for a potential fix.
My friend Ben came to the rescue! He bought a Pixel 2 XL at the same time I bought my Pixel 2, and has since upgraded to a later model. I messaged him about my woes, and he agreed to sell his unlockable phone to me. So, my Pixel 2 is still locked, but I'll still get the pleasure of giving an old handset a second life.
By the way, Lineage OS is a wonderful project worth supporting on Patreon!
Posted by Jacob Hall
William & Mary, as well as many other colleges, has Eduroam WiFi networks. Eduroam is a federation of educational institutions' authentication servers that allows members of each to login to the WiFi access points of others'.
I don't have much of an opinion about Eduroam itself, but the configuration script provided at connect.wm.edu did not work on my laptop running Fedora 34 (kernel 5.13.9, various versions of Python)
I followed the following steps to connect:
I emailed W&M IT asking for a new WiFi certificate.
The same day, they emailed me back two files: jwhall.crt.pem and jwhall.key.pem, the certificate and private key for my connection.
I connected to the Eduroam WiFi network on campus in Gnome's network settings as follows:
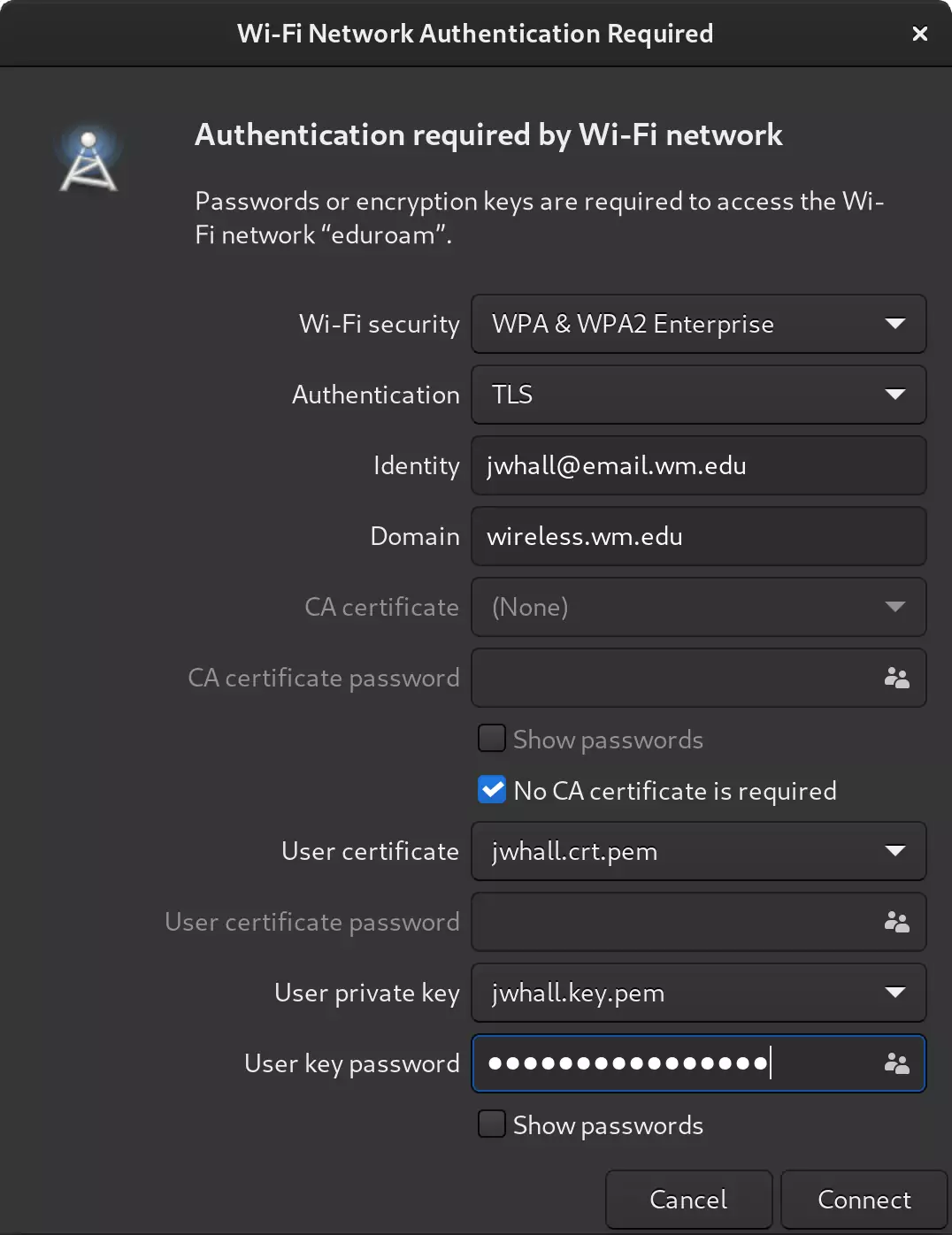
Once logged in to the network, a log-in window to W&M CAS was presented before granting me internet access.
Cheers to W&M IT for their help, though I hope certificate generation can be automated soon!
Posted by Jacob Hall
